
2022. 7. 1. 11:07ㆍC#/운영체제
[메모리 구조]

메모리 영역에 관해 공부하기 전에 프로그램이 어떤식으로 실행되는지 과정을 살펴 보자. 위 이미지는 프로그램의 정보를 읽어 메모리에 로드되는 과정을 보여준다. 프로그램이 실행하게 되면 OS는 메모리에 공간을 할당해준다. 할당해주는 메모리 공간은 4가지가 있다.
*메모리 구조
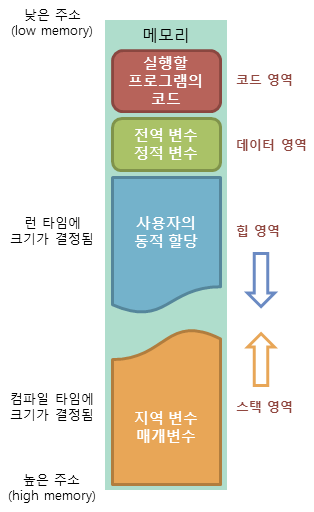
- 코드 영역
텍스트 영역은 코드를 실행하기 위해 저장되어 있는 영역을 말한다. 흔히 코드 영역이라고도 하는데 프로그램을 실행시키기 위해 구성되는 것들이 저장되는 영역이다. 한마디로 명령문들이 저장되는 것인데, 제어문, 함수, 상수들이 이 영역에 저장된다.
- 데이터 영역
데이터 영역은 우리가 작성한 전역변수, 정적변수 등이 저장되는 공간이다. 이들의 특징을 보면 보통 메인함수 전에 선언되어 프로그램이 끝날 때까지 메모리에 남아있는 변수들이라는 특징이 있다. 좀 더 구체적으로 데이터 영역도 크게 초기화된 변수 영역과 초기화되지 않는 변수 영역으로 나뉜다. 그 중 초기화되지 않는 변수 영역을 BSS(Block Started by Symbol)라고도 한다.
- 힙 영역
힙 영역은 쉽게 말해서 사용자에 의해 관리되는 영역이다. 흔히 동적으로 할당 할 변수들이 여기에 저장된다고 보면 된다. 이곳은 메모리의 낮은 주소에서 높은 주소의 방향으로 할당된다. 힙 영역은 런타임시 그 크기가 결정된다.
- 스택 영역
스택 영역은 함수의 호출과 관계되는 지역변수 매개변수들이 저장되는공간이다. 이는 메인함수안에서의 변수들도 포함된다 그리고 함수가 종료되면 해당 함수에 할당된 변수들을 메모리에서 해제시킨다. 스택 영역은 힙 영역과 반대로 높은 주소에서 낮은 주소의 방향으로 할당된다.
*Stack Overflow
만약 함수의 재귀 호출이 무한히 반복될 때, 스택 영역에 데이터가 계속해서 쌓이고, 스택 영역을 넘어 데이터가 저장된다. 스택 영역을 넘어 데이터가 저장된 순간 Stack Overflow가 발생한다. 마찬가지로 Heap Overflow도 존재한다.
*메모리 주소
메모리 구조를 설명할때 나오는 Low address, High address란 무엇일까?
컴퓨터를 다루다보면 '32bit 운영체제', '64bit 운영체제' 라는 단어를 쉽게 접할 수 잇다. 또한 Windows 운영체제 사용자들은 한 번쯤 x86(32비트), x64(64비트)라는 말을 봤을 것이다. 32비트라는 말은 0000 0000 0000 0000 0000 0000 0000 0000부터 1로 가득 채워진, 즉 232 경우의 수를 갖고 64
비트는 264 의 경우의 수를 갖는다. 이 둘의 차이는 생각보다 매우 크다.
- 232 = 4,294,967,296 (약 43억)
- 264 = 18,466,744,073,709,551,616 (약1844경)
64bit 운영체제가 데이터 처리 단위가 훨씬 많다보니 당연히 CPU 처리도 빠르고 새로운 명령어들도 만들 수 있다. 그렇다보니 64bit 운영체제에서는 32bit프로그램을 돌릴 수 있지만, 32bit에서는 64bit용프로그램을 돌릴 수 없는 것이다.
32bit와 64bit를 왜 설명하느냐?
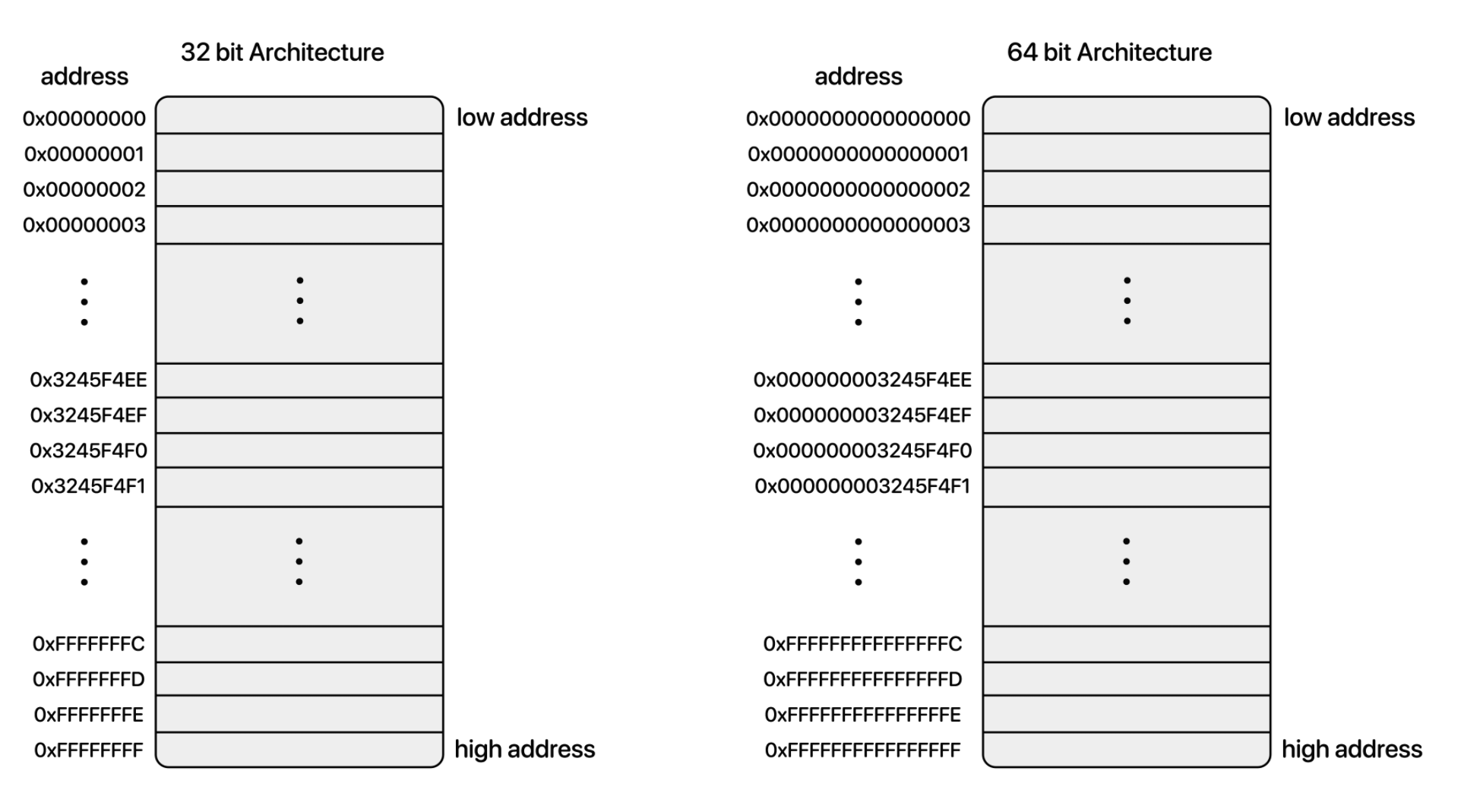
이 것이 메모리와도 연관이 있기 때문이다. 메모리 한칸은 1byte의 크기를 갖고 있다. 그리고 32bit 운영체제는32개의 비트, 즉 4바이트 길이의 주소를 갖는다. 즉 메모리를 4,294,967,296개의 주소공간을 가리킬 수 있고 주소의 기본 단위인 1 btye * 232 = 4,294,967,296 byte 까지 인식가능하다. 즉 옛날 32bit 운영체제의 경우 메모리를 4GB밖에 설치할 수 없다.
- 4,294,967,296 = 232 B = 4 * 230 B = 4GB
그럼 64bit 운영체제는 어떨까?
32bit 운영체제의 메모리 계산법을 똑같이 적용해본다면 16EB(엑사바이트) = 16384TB(테라바이트)라는값이 나오므로 이론적으론 16EB까지 메모리를 설치할 수 있다.
하지만 이 주소를 2진수로 표현하기에는 너무 길어 우리는 보통 편의상 16진수로 표현한다.
- 32bit : 0x00000000 ~ 0xFFFFFFFF
- 64bit : 0x0000000000000000 ~ 0xFFFFFFFFFFFFFFFF
[바이트 정렬]
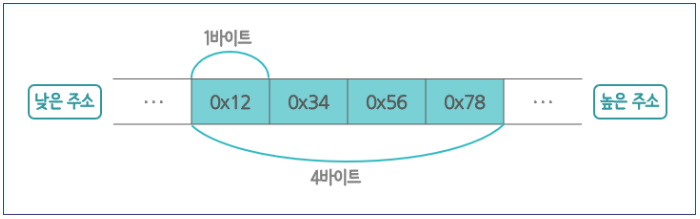
앞에서 메모리 주소는 바이트 단위로 한다고 했다. 만약 어떤 변수에 0x12(10진수로 18)라는 값을 넣었다면 이는 1바이트 이기 때문에 1바이트 메모리에 그대로 저장된다. 하지만 0x12345678이라는 값 (10진수로는 305419896)을 넣으면 어떻게 될까?
0x12345678는 총 4바이트의 크기이기 때문에 1바이트 4개로 나눠어서 저장해야한다. 이렇게 2바이트 이상의 메모리를 사용할 때 어떤 순서로 배열할 것인지가 '바이트 정렬'이다.
*Big-endian, Little-endian
바이트 정렬에는 보통 빅 엔디언과 리틀 엔디언으로 나뉘어 진다.
Big-endian : 낮은 주소에 데이터의 높은 바이트(MSB, Most Significant Bit)부터 저장하는 방식
-> 쉽게 생각하면 평소 우리가 숫자를 사용하는 선형 방식과 같은 방식
- 디버깅이 편하다.
- 비교연산이 빠르다.
메모리에 저장된 순서 그대로 읽을 수 있 있으니 이해하기 쉽기 때문이다. 또한 두 수중 어느 수가 더 큰 가를 비교할때는 가장 큰 수부터 비교한다. 빅 엔디엔으로 저장하면 메모리 가장 앞에 큰수가 와 있으므로 비교에 있어 빠르다.
Little-endian : 낮은 주소에 데이터의 낮은 바이트(LSB, Least Significant Bit)부터 저장하는 방식

-> 평소 우리가 숫자를 사용하는 선형 방식과는 거꾸로, 인텔이 사용하고 있는 방식
- 타입형 변환에 빠르다
- 계산연산이 빠르다.
만약 32비트 숫자인 0x2A는 리틀 엔디언으로 표현하면 2A 00 00 00이 되는데 이 표현에서 앞에 두 바이트만 떼어내면 하위 16비트 혹은 8비트를 바로 얻을 수 있다 또한 덧셈의 기본 원리가 낮은 수부터 더해서 해당 자리수를 넘어가는 수는 앞으로 넘겨줘서 더하는 방식인데 메모리 순서상 큰 수부터 계산하는 빅엔디언보다는 리틀엔디언 방식이 우리가 계산하는 방식과 동일하다.
*Struct는 어떻게 할당되는가?
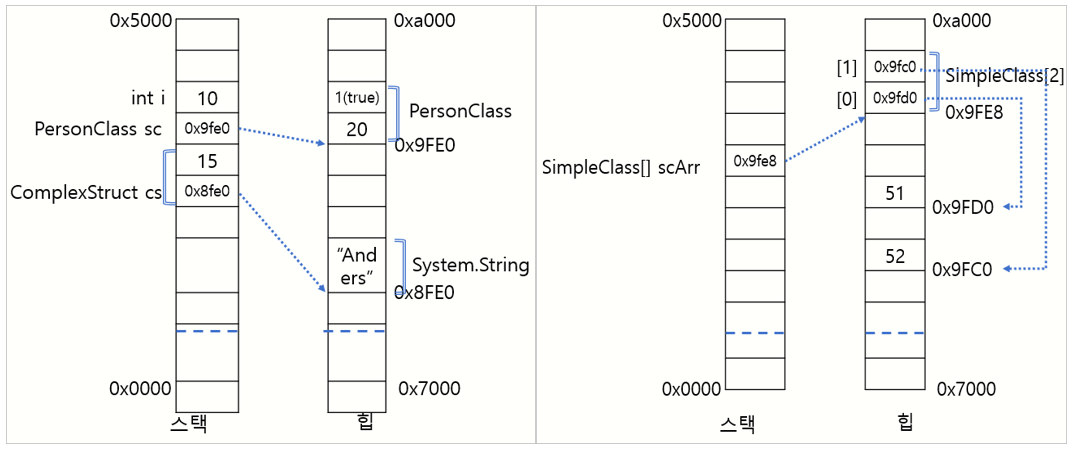
Struct/Class의 할당방식
- struct 내부에 값타입과 참조타입의 필드가 있을경우
- class 내부에 값타입과 참조타입의 필드가 있을경우
'C# > 운영체제' 카테고리의 다른 글
| [운영체제] 교착상태, deadlock (0) | 2022.07.04 |
|---|---|
| [운영체제] 프로세스와 쓰레드 (0) | 2022.07.04 |
| [운영체제] 메모리 관리, 페이징기법, 세그멘테이션, 가상메모리 (0) | 2022.07.01 |
| [운영체제] OS, 스케쥴링 (0) | 2022.07.01 |