
2022. 8. 24. 17:17ㆍUNITY/공부
드로우 콜

드로우 콜이란?
CPU가 GPU에게 이거 그려! 하고 명령을 호출하는 것.
한 프레임의 렌더링은 매 오브젝트를 순차적으로 그려주면서 오브젝트를 다 그리면 화면에 보여지게 되는 것이다. 오브젝트를 화면에 렌더링하기 전에 우선 해당 오브젝트가 렌더링 대상에 포함되는지 체크한다. 예를 들어, 현재 프레임 상에서 해당 오브젝트가 카메라의 시야밖에 있다면, 안 그래도 되는 것이므로 렌더링 대상에서 제외한다. 이런 검사를 Culing이라고 한다. 컬링을 거친 오브젝트가 렌더링되려면 CPU로부터 GPU에게 정보를 전달해야한다.
이렇게 한 프레임 마다 오브젝트를 하나하나 그릴 때 마다 정보들이 CPU에서 GPU로 전달되고 그려진다. 이 과정을 반복해서 렌더링한 후 모든 오브젝트들이 다 그려지면 한 프레임이 끝나고 화면에 출력된다. 이때 CPU가 GPU에게 렌더링하라고 명령을 보내는 것을 Draw Call이라고 한다.
CPU와 GPU는 어떻게 협업하는가?
GPU가 Mesh를 렌더링하려면 GPU 메모리에서 데이터를 읽어와야한다. 그러려면 그 전에 GPU 메모리에 데이터가 있어야 한다는 의미이다. 그래서 렌더링을 수행하기 전에 데이터 로딩이 이루어지면서 Mesh 정보가 GPU 메모리에 담기는 것이다. CPU가 HDD,SDD,SD카드 등의 스토리지에서 파일을 읽어들이고 데이터를 파싱하여 CPU메모리에 데이터를 올린다. 그 후 CPU 메모리의 데이터를 GPU 메모리로 복사하는 과정을 거친다.
이렇게 데이터를 메모리에 전달하는 과정을 매 프레임마다 수행하게 되면 성능 하락이 생길 수 밖에 없다. 따라서 로딩 시점 혹은 씬 전환 시점등에 메모리에 데이터를 올리거나 헤제한다. 즉, 게임이 실행되는 동안에는 데이터가 계쏙 메모리에 상주하게 된다. 텍스쳐, 쉐이더 등 렌더링에 필요하나 데이터 모두 GPU 메모리에 존재하고 있어야 한다.
Render State와 DP Call
렌더링 루프를 돌면서 어떤 오브젝트를 렌더링해야하는 시점이 오면 GPU에 어떤 텍스쳐, 버텍스, 쉐이더등을 사용해야할지 전달해줘야하는데 이런 정보들은 한번의 명령으로 처리되는 것이 아니라 순서대로 일일히 알려줘야한다. 그렇다고 일일히 하나씩 알려주는 것은 비효율적이니 GPU는 해당 정보를 담는 테이블을 가지고 있다. 이런 테이블을 Render State (렌더 상태) 라고 부른다.
렌더 상태의 테이블 정보들은 GPU 메모리의 어느 곳에 필요한 데이터가 있는지 데이터의 주소를 저장해둔다. CPU가 렌더 상태를 변경하는 명령을 보내면 GPU는 렌더 상태에다가 오브젝트를 그리기 위한 정보를 저장한다. CPU는 명령을 보내고 마지막으로 GPU에게 메시를 그리라는 명령을 보낸다. 이 명령을 Draw Primitive Call, 일명 DP Call이라고 한다.
GPU는 DP Call을 받으면 받아두었던 렌더 상태의 정보들을 기반으로 메시를 렌더링한다. 메시를 렌더링하고 난 뒤, CPU는 이제 또 다른 오브젝트를 렌더링하기 위해 상태 정보를 변경하는 명령을 보낸다. 이때 바뀔 필요가 없는 상태의 명령은 보내지 않는다. 이렇게 렌더 상태를 변경해주고 마지막으로 GPU가 DP Call을 받으면 또 바뀐 상태대로 렌더링을 하는 것이다.
이런 방식으로 CPU는 필요한 정보를 갱신하는 렌더 상태 변경 명령을 보내고, GPU는 그대로 렌더 상태를 변경하고, CPU는 다시 DP Call을 주면 GPU가 렌더링하는 과정을 반복한다.
Command Buffer
CPU가 GPU에게 명령을 보낸다고 표현했지만 사실 바로 명령을 주지 않고 중간에 한 단계를 거친다. 바로 명령을 보낸다면 GPU가 다른 작업을 수행하고 있을 시, CPU는 명령을 주고 제 할일을 해야하기 때문에 GPU가 하던 일을 마칠 때까지 기다려야하는 불상사가 생길 것이다. 그래서 CPU는 명령을 버퍼에 쌓아놓고, GPU는 버퍼에서 명령을 가져가서 할 일을 하는 방식으로 일한다. 이렇게 일을 쌓아두는 버퍼를 Command Buffer라고 부른다. 커멘드 버퍼는 FIFO방식으로 명령을 처리한다.
CPU의 성능에 의존하는 드로우콜
렌더링이기 때문에 드로우 콜은 CPU보다 GPU의 영향이 크다고 생각하지만, GPU가 그리기 위한 신호들을 모두 CPU가 GPU에 맞게 변형하여 보내게 된다. 이런 과정들은 곧 CPU바운더리의 오버헤드이며, 텍스쳐의 크기를 줄이거나, 폴리곤 수를 줄인다고 해서 드로우콜의 성능이 좋아지는 것은 아니다. 횟수를 줄여야한다.
드로우 콜의 발생 조건
기본적으로 오브젝트를 하나 그릴 때 Mesh1개, Meterial 1개라면 드로우콜이 한번 발생한다. 즉 Batch가 1이 된다.
하지만 오브젝트 하나가 메시 여러개로 구성되어 있는 경우 예를 들어, 메시가 17개라면 드로우 콜도 17번 발생한다. 이 메시들이 1개의 메테리얼을 공유하더라도 메시 개수대로 17번의 드로우 콜이 필요하다. 또한 하나의 메시에 메테리얼이 여러 개여도 그 개수만큼의 드로우 콜이 필요하다.
쉐이더에 의해서도 드로우 콜이 늘어날 수 있다. 쉐이더 내에는 멀티 패스(Multi Pass)라고, 두번 이상 렌더링을 거치는 경우가 존재한다. 대표적인 예가 카툰렌더링이다. 첫번째 패스에서 모델을 렌더링하고, 두번째 패스에서 모델 외곽선을 그려준다. 렌더링을 두번 해야하므로 드로우 콜이 두번 발생한다. 따라서 메테리얼이하나라고 해서 무조건 하나의 드로우 콜만 발생하는 것이 아니다.
특히 모바일의 경우 드로우 콜 횟수가 크면 성능에 많은 영향을 끼칠 수 있으므로 드로우 콜을 신경쓰면서 최대한 줄여야한다. PC에서는 1000개가 넘어도 가능하지만, 모바일에서는 100개도 많은 편이다. 최신 모바일 디바이스는 200개가 넘는 것도 가능하지만, 디바이스마다 다르므로 드로우 콜의 기준을 확정 지을 수 없다. 또 드로우 콜을 개수로 따져왔지만, 사실 드로우 콜마다도 비용이 각각 다르다. 당연히 상태 변경이 많이 필요한 드로우 콜과 적게 필요한 드로우 콜은 비용차이가 날 것이다.
Batch & SetPass
유니티에서는 드로우 콜을 Batch와 SetPass 두 용어로 나누어 표시한다.
- Batch : DP Call과 상태 변경들을 합친 넓은 의미의 드로우 콜
- SetPass Call : SetPass는 쉐이더로 인한 렌더링 패스 횟수를 의미
만약 Batch가 10번 SetPass가 1번 발생했다면 10번의 드로우 콜 동안 쉐이더 번경은 없었고 메시 및 트랜스 폼 정보 등 최소한의 상태 변경만 이루어졌다는 것을 의미한다. SetPass도 10번 일어났따면 드로우 콜 마다 매번 쉐이더의 변경이 이뤄졌고, 경우에 따라 많은 상태 변경이 일어났다는 것을 의미한다. 당연히 이 경우가 성능을 더 많이 잡아먹을 것이다.
SetPass에서 알려주는 상태 변경은 쉐이더의 변경 혹은 쉐이더 파라미터들의 변경이 일어나는 경우이다. 씬 오브젝트를 렌더링하는 과정에서 메테리얼이 바뀌면 그에 따라 쉐이더 및 파라미터들이 바뀌고 SetPass 카운트가 증가한다. 이 때 많은 상태 변경이 일어나기 때문에 SetPass 횟수도 중요하다.
만약 게임이 CPU바운드이고 GPU에 명령을 보내는 과정, 즉 드로우 콜이 병목이라면 SetPass Call횟수를 줄이는게 가장 효율적이다. 서로 다른 메시를 사용한다고 SetPass Call이 늘어나는 것은 아니다. 다른 메시라도 같은 메테리얼을 쓰면 늘어나지 않는다. SetPass Call이 적으면 Batch 구성이 잘 되어있다는 의미다.
Batching
드로우 콜을 줄이는 작업
유니티에서 배칭을 활용함으로써 드로우 콜을 많이 줄일 수있기 때문에 거의 필수적으로 사용해야하는 기능이다. 여러 Batch를 묶어서 하나의 Batch로 만드는 것을 Batching이라고 한다. 즉 Batching은 여러 번 드로우 콜할 상황을 하나의 드로우 콜로 묶는 과정이다.
다른 오브젝트, 메시를 사용하더라도 메테리얼이 같다면 하나의 Batch로 구성할 수 있다. 여러 개의 다른 오브젝트들이지만 메테리얼이 같다면 배칭처리를 통해 한번에 그리는 것이 가능하다는 얘기다. 여기서 메테리얼이 같다는 것은 동일한 메테리얼 인스턴스를 의미한다. 같은 텍스쳐, 같은 쉐이더를 이용한 메테리얼이라도 따로 두개를 만들어 두면 그 두개는 다른 메테리얼로 인식, 배칭이 되지 않는다. 스크립트에서 메테리얼에 접근할 때도 이런 이유에서 조심해야할 것이다.
GetComponent<Renderer>().material.color = Color.red;
위와 같이 메테리얼의 속성을 수정하면 메테리얼이 수정되는 것이 아니라 메테리얼의 복사본이 생성된다. 대신 Renderer.sharedMaterial로 수정하면 복삽손이 생성되지 않고 공유된 메테리얼 원본이 수정된다. 단, 공유하고 있떤 다른 친구들도 수정된 결과가 적용되니 인지하고 유의하여 사용하자.
배칭을 하기 위해서는 하나의 메테리얼을 여러 메시들이 공유해서 사용해야한다. 즉 텍스쳐 하나를 공유해서 사용한다는 뜻이다. 그래서 텍스쳐 하나에다가 여러 개의 텍스쳐를 합쳐서 사용하는 텍스쳐 아틀라스(Texture Atlas)기법으로 리소스가 제작된다. 텍스쳐 아틀라스는 아래에서 설명할테니 잠시 넘어가겠다.
그러면 모든 메시의 텍스쳐를 1개에다가 때려박으면 되나?
안된다. 해상도 문제를 고려해야한다. 512해상도의 텍스쳐 16개를합치면 2048 해상도의 텍스쳐가 필요하다. 구형 디바이스에서는 성능 저하가 발생할 수 있기 때문에 해상도를 고려하면서 작업해야한다.
Batching에는 Static Batching, Dynamic Batching 두 종류가 있다.
Edit > Project Settings > Player에서 Static Batching, Dynamic batching을 체크할 수 있다.
체크하면 조건에 맞는 경우 자동 배칭이 된다. 간단하게 사용할 수 있지만 배칭 기법은 특성과 한계가 존재하니 알고 쓰도록 하자.
Static Batching
정적인 오브젝트를 위한 배칭기법.
주로 배경 오브젝트들이 해당된다. Static Batching을 적용할 오브젝트라면 인스펙터에서 Static을 체크해줘야 한다. 이걸 켜주면 스태틱 배칭의 대상으로 인정받아 로딩타임에서 자동으로 배칭처리가 될 것이다.
장점
Dynamin Batching보다 효율적이다. 런타임에서 수행할 버텍스 연산이 없기 때문이다.
메테리얼이 1개라고 무조건 1개의 배치로 구성되는 건 아니고 라이트맵, 라이트프로브, 동적라이트 영향 여부등 다양한 조건에 의해서 배칭이 나뉠 수 있따.
로딩타임에서 배칭처리를 하기 때문에 처음부터 씬에 존재해야 스태틱 배칭에 껴준다. 나중에 추가되는 정적인 오브젝트들은 자동으로 스태틱 배칭이되지 않고 StaticBatchingUtility.Combine()로 런타임 상에 추가된 정적인 오브젝트들도 배칭처리를 받을 수 있게 해줘야한다. 하지만 스태틱 배칭에 껴주기 위해 데이터를 수집하고 메시를 재생성해야하기 때문에 많은 시간이 필요하므로 되도록 자제하도록 하자.
단점
메모리가 추가로 필요하다
다른 메시들을 메테리얼이 같다는 이유로 한 번에 그리는 것이다. 따라서 배칭처리를 하면 오브젝트들을 합쳐서 내부적으로 하나의 메시로 만들어 놓는데, 1개의 메시만 사용하더라도 여러 개의 메시를 합친, 거대한 메시를 만들기 위한 추가 메모리가 필요한 것이다. 이렇게 새로 만들어낸 메시를 GPU가 가져가서 그대로 화면에 렌더링하므로 드로우 콜은 1번으로 처리될 수 있었던 것이다. 물론 메모리를 희생하더라도 드로우 콜을 줄일 수 있기 때문에 런타임 성능은 높일 수 있다. 하지만 메모리에 문제가 생긴다면 줄일필요는 있다.
Dynamic Batching
Static과 반대로, Static이 체크되지 않은 동적인 오브젝트들 중 동일한 메테리얼을 사용하고 특정 조건을 만족하는 오브젝트들을 대상으로 배칭처리를 하는 기능이다. 역시 Dynamic Batching을 체크해주면 별도의 추가 작업이 필요하진 않고 알아서 해준다. 하지만 제약사항이 많다. 런타임상에 배칭처리 되기 때문에 어쩔 수 없다. 매 프레임 씬에서 동적인 오브젝트들의 버텍스를 모아서 합쳐주는 과정을 거친다. 모은 버텍스들을 다이나믹 배칭에 쓰이는 버텍스 버퍼와 인덱스 버퍼에 담으면 GPU가 이것을 가져가서 렌더링한다. 결과적으로 매번 데이터 구축과 갱신이 발생하기 때문에 메 프레임마다 오버헤드가 발생한다.
일반적으로 렌더링할때는 버텍스 쉐이더에서 월드스페이스로 변환하는 과정에서 GPU에서 고속연산이 이뤄지는데, 다이나믹 배칭을 위해서는 오브젝트의 버텍스를 월드스페이스로 변환하는 연산이 CPU에서 이뤄진다. 따라서 이 연산과정이 드로우 콜보다 시간이 오래걸리면 오히려 효율이 떨어지는 것이다. 배칭 오버헤드와 드로우 콜 시간을 비교하여 빠른 쪽으로 선택하는 것이 맞다.
Sprite Atlas
스프라이트들을 하나의 아틀라스로 합치면 Batch를 줄일 수 있다. 이를 위해 약간의 설정 변경이 필요한데 방법은 아래와 같다.
1. Edit > Project Settings > Editor > Sprite Packer의 Mode를 변경한다. 옵션은 다음과 같다.
- 빌드에 대해 활성화(Enabled for Builds) : 플레이 모드에서가 아니라 빌드에 대해서만 패킹을 사용하고 싶을때
- 항상 활성화(Always Enabled) : 패킹된 스프라이트가 플레이 모두 동안 스프라이트 아틀라스에서 텍스쳐를 확인하게 만들고, 편집 모드에서 원본 텍스쳐의 텍스쳐를 확인하게 만들고 싶을때 사용
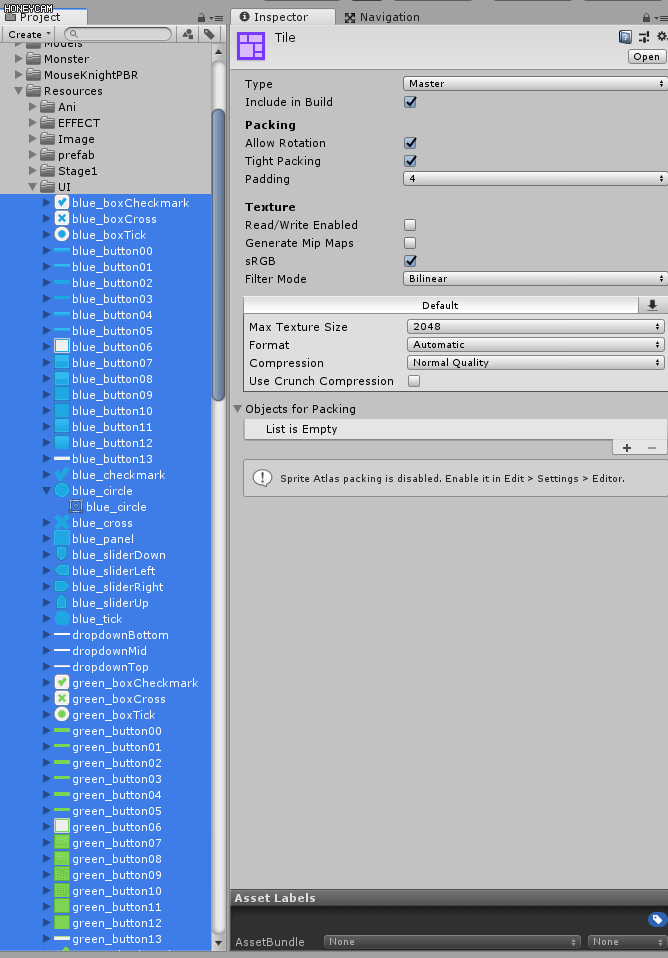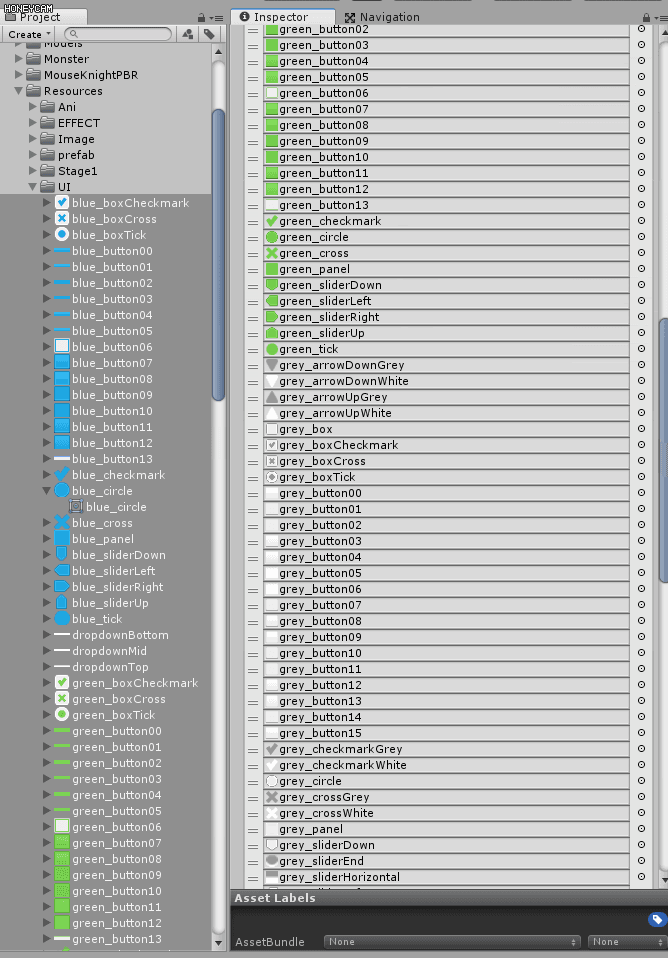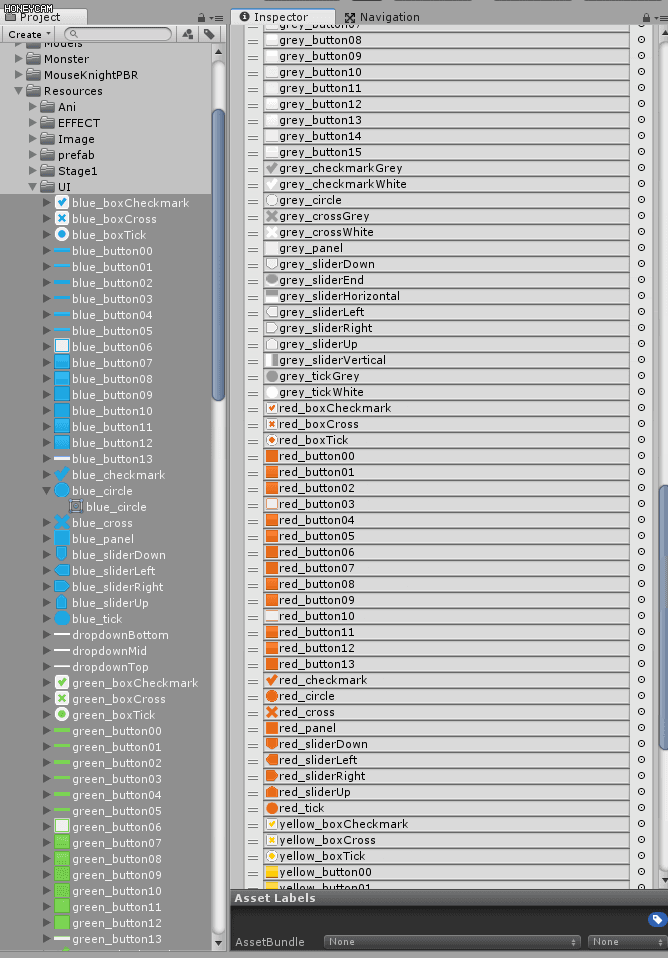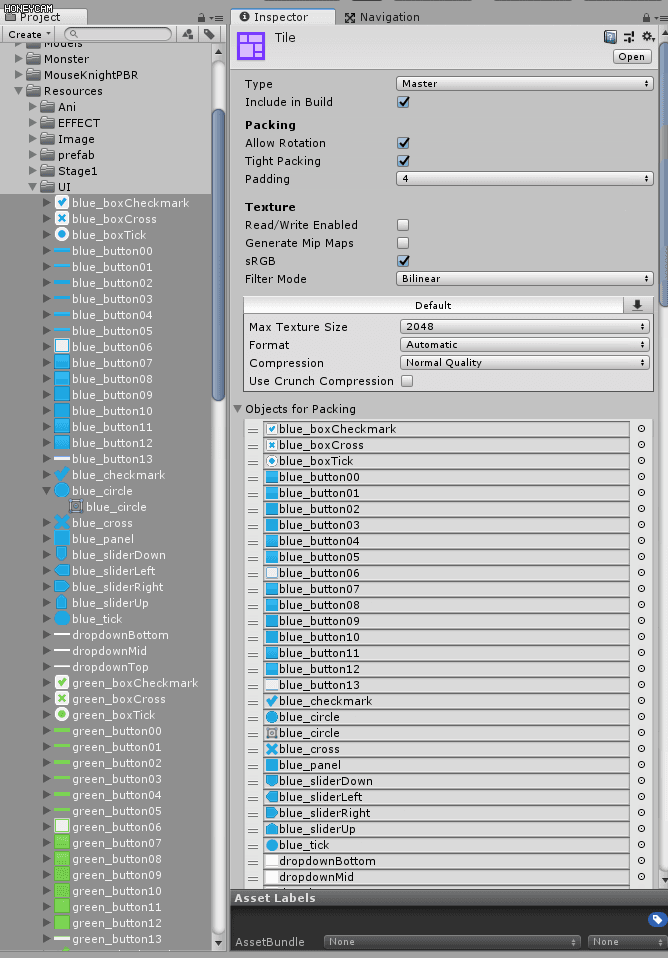
2. Project > Create > Sprite Atlas를 선택해서 스프라이트 아틀라스 에셋을 생성한다.
Inspector에서 설정이 가능하다. Objects for Packing에서 원하는 스프라이트를 추가할 수 있다. 폴더나 여러개의 스프라아티를 통째로 드래그 앤 드롭도 가능하다.
헷갈리는 용어 정리
*CPU 바운드 : 프로세스 진행 속도가 CPU 속도에 의해 제한됨을 의미한다. 여기서 바운드는 ~위주의 라고 해석하면 쉽다.
- https://funfunhanblog.tistory.com/301
- https://metamon9.tistory.com/6
- https://funfunhanblog.tistory.com/44
- https://landwhale2.github.io/network/94/
- https://mentum.tistory.com/55?category=6907
'UNITY > 공부' 카테고리의 다른 글
| [Unity] Unity의 enabled, isActiveAndEnabled 및 activeInHierarchy의 차이점 (0) | 2023.05.11 |
|---|---|
| [Unity] 현재 실행중인 애니메이터의 길이를 구하는 방법 GetCurrentAnimatorStateInfo (0) | 2023.02.22 |
| [Unity]유니티에 csv, 엑셀, txt 파일 불러오기 (0) | 2021.06.24 |
| [Unity] Input.GetAxis와 Input.GetAxisRaw (0) | 2021.06.22 |
| [Unity] GetButton, GetButtonDown, GetButtonUp (0) | 2021.06.22 |