
2022. 8. 17. 20:54ㆍSTUDY/CS
[객체 지향]
객체 지향 프로그래밍이란?(OPP : Object Oriented Programming)
객체 지향 프로그래밍은 컴퓨터 프로그래밍 페러다임 중 하나로 프로그래밍에서 필요한 데이터를 추상화시켜 상태의 행위를 가진 객체를 만들고 그 객체들 간의 유기적인 상호작용을 통해 로직을 구성하는 프로그래밍 방법이다. 말 그대로 객체 지향은 기능이 아닌 객체가 중심이 되어 "누가 어떤 일을 할 것인가?" 가 핵심이 된다. 즉 객체를 도출하고 각각의 역할을 정의해 나가는 것에 초점을 맞춘다.
객체 지향에 대한 이해를 위해 절차 지향 프로그래밍과 비교하면서 설명하겠다.
객체 지향 프로그래밍은 객체가 중심이 된다면 절차 지향 프로그래밍은 무엇이 중심이 될까?
절차 지향은 기능 중심으로 바라보는 방식으로 "무엇을 어떤 절차로 할 것인가?" 가 핵심이 된다. 즉, 어떤 기능을 어떤 순서로 처리하는가에 초점을 맞춘다.
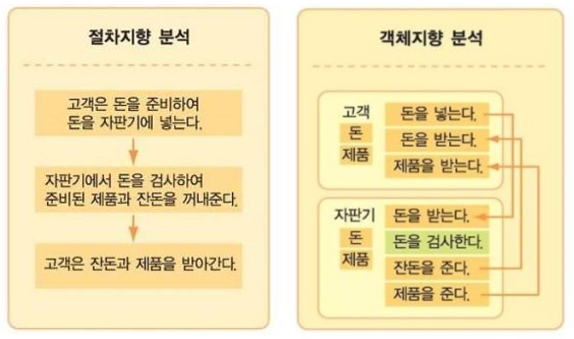
-> 절자 지향은 어떠한 순서대로 흘러가느냐가 포인트고, 객체 지향은 돈을_넣는다, 돈을_받는다 등 객체가 어떤 일을 하는가에 초점을 둔다
객체 지향 프로그래밍이 객체가 중심이라는건 알겠다. 이제 객체 지향의 장단점을 절차 지향과 비교하며 알아보자
객체 지향 vs 절차 지향
객체 지향 프로그래밍의 장점
- 모듈화, 캡슐화로 인해 유지보수에 용이하다.
- 상속, 다향성등으로 인해 재사용성이 증가한다.
- 모듈화등 객체 단위로 분업이 가능하여 여러 명이 같이 개발하는 대형 프로젝트에 적합하다.
객체 지향 프로그래밍의 단점
- 캡슐화와 격리구조등으로 인해 절차지향 프로그래밍과 비교하면 상대적으로 실행 속도가 느리다.
- 객체를 어떻게 처리할 것인가에 대한 정확한 이해가 필요하기에 설계단계부터 많은 시간이 소모된다.
절차 지향 프로그램밍의 장점
- 객체나 클래스를 만들 필요없이 바로 프로그램을 코딩할 수 있다.
- 컴퓨터의 처리구조와 유사해 실행속도가 빠르다.
절차 지향 프로그래밍의 단점
- 모든 구성요소가 유기적으로 연결되어 있다는 말은, 하나가 고장났을때 시스템 전체가 고장난다는 말과 같다. 즉 유지보수가 어렵다.
- 코드가 길어지면 가독성이 매우 떨어진다.
객체지향 프로그래밍의 반대는 절차지향 프로그래밍이다?
이말은 틀리다. 왜냐하면 절차지향 프로그래밍이라고 해서 객체를 다루지 않는 것이 아니다. 마찬가지로 객체 지향이라고 해서 절차가 없는것이 아니다. 어디까지나 프로그래밍 접근 방법이 조금 상이할 뿐이다. 대개 절차지향 프로그래밍은' 데이터를 중심으로 함수'를 만들고 객체지향은 '데이터와 기능(함수)들을 묶어 하나의 객체'로 만들어 사용한다. 그리고 절차지향이라는 말도 정확한 표현은 아니고 절차적 프로그래밍이라고 하는데, 기본적인 절차라는 틀을 깨지 않는 선에서 객체 지향적 프로그래밍을 하느냐 마느냐의 차이라고 볼 수 있다.
-> 사실 웃긴게 애초에 프로그래밍이 절차적인 기반을 두고 있는데 절차를 지향한다는게 웃긴 표현이다...
그럼 객체지향과 절차적 언어를 어떤 기준으로 구분하는가?
- 캡슐화, 다향성, 클래스 상속을 지원하는가?
- 데이터 접근 제한을 걸 수 있는가?
보통 위 기준을 만족하면 객체지향, 만족하지 않으면 절차적 성격이 강해진다.
*객체지향 프로그래밍의 특징
이제 객체지향 프로그래밍이 먼지를 이해했다. 그렇다면 좀더 구체적으로 객체지향 프로그래밍은 어떤 특징을 가지고 있나 알아보자
*캡슐화
데이터와 코드의 형태를 외부로부터 알 수 없게하고 데이터의 구조와 역할, 기능을 하나의 캡슐형태로 만드는 것을 말한다. 즉, 객체 내부 구현을 외부로부터 감추는 것(정보 은닉)을 말한다. 그렇다면 왜 외부로부터 알 수 없게 감추는 걸까? 그 이유는 내부구현을 숨김으로 인하여 내부구현의 변화가 발생하더라도 외부 객체에 변화의 영향이 퍼져나가지 않도록 막기 위함이다.
캡슐화에 대해 얘기할때 가장 많이 사용하는 예시
getter/setter를 생각해보자 어떤 변수를 private로 선언하고 getter/setter를 사용한 것을 캡슐화 했다고 한다. 정확히는 데이터 캡슐화다. 하지만 이러한 데이터 캡슐화만으로는 캡슐화의 목적을 달성하지 못한다. getter가 있다는 건 어떤 로직을 수행하기 위해 해당 데이터가 필요하다는 의미고, 그 로직 또한 또다른 객체에서 수행될 것이다. 그렇다면 getter의 return type 이 바뀐다면? 또 다른 객체 역시 내용이 변경될 수 밖에 없다. 이런 케이스를 '객체의 내부구현이 드러난다' 고 한다. 캡슐화의 목적이 내부구현을 숨기는 건데 데이터 캡슐화만으로는 완벽하게 숨기는게 힘든 상황이 발생한다.
결국 변경될 수 있는 모든 것을 감추는 것이 궁극적인 캡슐화이다. 중요한 것은 이를 지키기 위해 고민해야 하며 응집도는 높이고, 결합도는 낮추려고 끊임없이 고민하는 것이 중요하다.
*추상화
인터넷에 검색해보면 '객체의 공통적인 속성과 기능을 추출하여 정의하는 것을 말한다'고 나온다. 이게 무슨말일까?
강아지 클래스가 있고 고양이 클래스가 있을때 이들의 공통점을 묶어서 상위 클래스를 만든다면 이는 추상화 한것이다. 그런데 만약 강아지만 하는 행동이 있고, 고양이만 하는 행동이 있다고 해보자. 이 행동들은 추상화하지 않고 각 클래스안에만 존재하게끔 하면된다. 이러한 방식으로 객체의 공통적인 속성과 기능들을 추출하고 그 과정에서 불필요한 것을 지우고 핵심을 남겨두는 과정을 추상화라고 한다.
결국 중요한것은 불필요한 것을 지우고 핵심을 남겨둔다는 추상화의 기본 사고를 기억하면서 여러 가지 상황에 적용해야한다.
*상속
상위 클래스의 변수 혹은 메소드와 같은 것들을 하위 클래스가 이어 받는 것을 말한다. 상속으로 인해 코드를 재사용할 수 있다는 장점이 존재한다.
*상속의 문제점
뭐든 장점만 있을리가 없지...
- 상위 클래스에 강하게 결합한다
예를 들어 상위 클래스에 string을 반환하는 메서드가 있다고 해보자. 이를 갑자기 char로 수정한다면 하위 클래스에서 해당 메서드를 사용하고 있다면 모조리 고쳐야 한다. 이런식으로 하위 클래스는 상위 클래스와 강하게 결합하게 되고 그로인해 응집력은 낮아지고 수동적인 객체가 된다는 단점이 존재한다.

- 캡슐화를 깨트린다.
뿐만 아니라, 기능 확장을 위해 하위 클래스에서 오버라이딩했다면 캡슐화를 깨는것이다. 캡슐화를 위해서는 외부에서 메서드를 가져다가 사용만 해야하는데, 오버라이딩은 구현을 수정하는 일이기 때문이다. 이렇게 오버라이딩할때, 문제가 없는지 상위 클래스의 내부 구현을 반드시 확인해야한다. 만약 내부구현을 모른채 재정의한다면 문제가 발생할 수 있다
-> 사실 상위클래스의 내부 구현을 알아야 한다는 사실 자체가 캡슐화를 깬다…
대표적으로 '정사각형 - 직사각형 문제'가 있다.
상속은 is-a관계가 성립할때 사용하라고 많이들 하는데 -> 개는 동물이다(o). 물고기는 광어다(x)
'정사각형은 직사각형이다'는 그냥 봤을때는 is-a관계다. (틀린말은 아니니깐…) 그래서 정사각형 클래스가 직사각형 클래스를 상속받아 구현되었다고 가정해보자. 가로-세로의 길이를 변경하는 메소드를 상속받아 사용중이라면 직사각형은 가로-세로의 길이가 달라도 되기 때문에 각각 다른 값으로 가로-세로를 변경할 것이다. 이는 정사각형을 정의가 아니기 때문에 따로 재정의를 해서 사용해야 할 것이다.
이렇듯 상위 객체의 내부 구현을 제대로 확인하지 않고 대충 메소드만 받아온다던지 하면 문제가 생길 수 있다. -> 정확하게 알아야 한다는 것은 캡슐화를 깨트리는 것..
*다향성
상속과 연관이 있는 개념으로 한 객체가 다른 여러형태로 재구성되는 것을 말한다.
*오버라이드 : 하위 클래스(자식)가 상위 클래스(부모)에서 만들어진 메서드를 자신의 입맛대로 다시 재창조해서 사용하는 것을 말한다.

-> virtual / override로 구현
-> base로 부모 메서드 접근도 가능
*오버로드 : 하나의 클래스 안에서 같은 이름의 메서드를 사용하지만 각 메서드마다 다른 용도로 사용되며 그 결과물도 다르게 구현하는 것을 말한다.

-> 매개변수를 달리하거나, 리턴타입을 달리하거나..
총정리 : 결국 객체 지향 프로그래밍이란 어떤 대상을 추상화여 공통점을 찾고, 그것을 캡슐화 과정을 통해 정보은닉등을 하고, 이를 새로운 객체가 상속을 받아 재사용이 가능하게 해준다. 그리고 상속받은 객체는 다향성을 통해 기능을 수정 또는 추가하여 재사용할 수 있다.
객체 지향 프로그래밍의 특징과 장단점에 대해 알아보았다. 이번에는 객체지향 개발 5대 원리에 대해 알아보겠다. 우리 삶에도 원리/원칙이 있듯이 객체지향을 어떻게 하면 더 잘 만들 수 있을까에 대한 입증된 원리들에 대해 알아보자
[추가내용]
*Virtual Table
어떤 한 클래스가 해당 클래스 혹은 Base클래스에서 하나 이상의 가상메서드를 갖는다면, 해당 클래스의 Method Table metadata내에 virtual table을 갖게 된다.
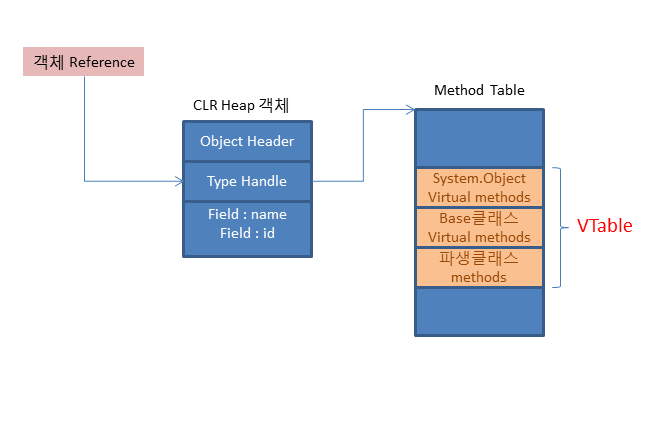
Vtable을 객체 레퍼런스가 가리키는 heap상 객체의 type Handle이라는 곳의 Method table내에 위치한다.
기본적으로 모든 클래스는 System.Object 클래스로부터 상속 받기 때문에 모든 클래스에는 Vtable이 존재한다. 여기에서 base클래스에 가상메서드가 없다면 VTable에 base클래스의 메서드를 추가하지 않는다.
C#에서 파생클래스가 Base클래스의 메서드와 동일한 이름을 가지게 하는 방법으로는 오버라이딩과 hiding이 있다.
- Method Overriding

오버라이딩을 이해하기 위해선 2가지를 먼저 알야아한다.
- 클래스로부터 객체를 생성되어 어떤 변수에 할당되었을때, 변수의 타입에 상관없이 해당 클래스의 Method Table 사용
- 만약 파생클래스의 객체가 보다 상위의 base클래스의 변수에 할당된다면 그 변수는 base클래스의 안에 있는 변수나 메서드만 사용 가능하다.
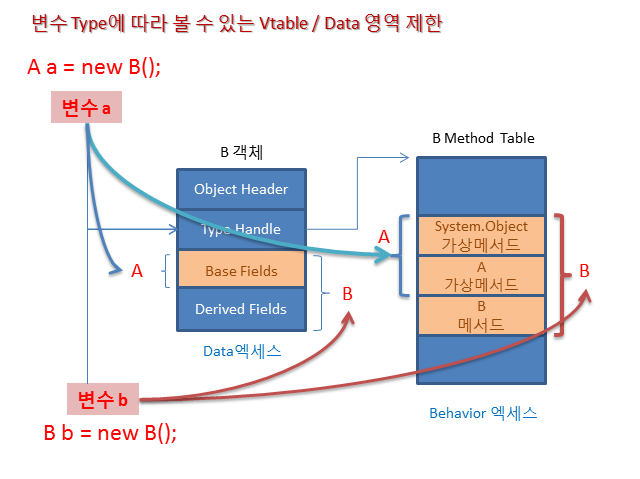
- A a = new B();
a라는 변수가 base클래스 변수이므로 Run1()은 base의 메서드로 할당된다.
- B b = new B();
B클래스의 Run1() 메서드가 할당된다.

-> A.Run1()자리에 B.Run1()이 들어간 것을 알 수 있음
Base클래스의 virtual 메서드를 파생클래스에서 오버라이드하면 파생클래스의 vtable에 별도로 추가하는게 아니라 base클래스 메서드 포인터에 넣는다.
즉, [base클래스] [변수] = new [파생클래스](); 로 선언하면 base클래스의 메서드가 호출되지만 우리가 평소에 쓰는 형태, [파생클래스] [변수] = new [파생클래스]();로 선언하면 base클래스의 메서드가 저장되어있을 자리에 파생클래스의 메서드가 들어가 override 된것이다.
- Method Hiding
만약 오버라이딩을 하지 않고 그냥 base 클래스와 메서드명이 같으면 어떻게 될까? 아까 오버라이딩하게 되면 base클래스의 메서드를 덮어씌운다는 것을 알았다. 하지만 하이딩은 그건 그대로 두고 새로운 메서드를 추가해서 해당 메서드가 나오게끔 하는 것이다.
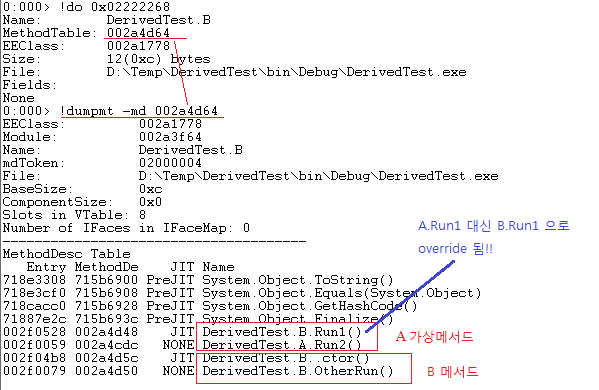
-> 기존 메서드를 덮어씌우는 오버라이딩과 방식이 다름
*IDisposable
dispose의 단어 자체의 의미가 '제거하다, 처분하다' 라는 뜻을 가지고 있다. 즉 제거 가능한, 사용 후 버리게 되어있는, 일회용의 란 뜻
C#에서 뭘 사용한다는 거고 뭘 제거한다는 것일까?
메모리다. 메모리를 썼으면 해제도 해야한다. 그런데 GC가 알아서 더 이상 사용하지 않는 개체들을 소거해가는데 왜 Dispose가 필요할까?
- GC 관리되지 않는 리소스들은 인식하지 못한다.
- GC가 어느 시점에 일어나는지를 모른다.
- GC가 너무 자주 발생하게 되면 오버헤드가 일어난다.
IDisposable을 상속 받고 Dispose()를 구현하면 TestClass가 종료될때 Dispose가 호출된다.
근데 using은 멀까?
using을 추가하고 괄호 묶어야 t가 언제까지 사용할지를 알려주지 않기 때문에 Dispose() 실행되지 않는다. 때문에 using을 추가한다.
사람은 언제나 실수를 할 수 있다. 개발자가 Dispose를 명시적으로 호출해준다는 보장만 있다면 괜찮으나, 언제든 실수를 할 수 있다. 이 때문에 좀더 안정적인 클래스 구현을 위해 종료자가 필요한 것이다.
'STUDY > CS' 카테고리의 다른 글
| 어셈블리어에 대한 개념 정리 (0) | 2024.09.28 |
|---|---|
| C# GC(Garbage Collector) 가비지 컬렉터 (0) | 2022.08.17 |
| dll, lib (0) | 2022.07.01 |
| 닷넷 프레임 워크 구조 (0) | 2022.07.01 |
| 메모리 구조, 바이트 정렬 (0) | 2022.07.01 |